观点五:
在看数据之前,我先说说自己的想法:
1. 把钱看成连续的,分完以后再修正bug:a)为了使最小单位为0.01,最后结果精确到十分位即可,零头全部倒给最后一个人(或者从最后一个人那里出)b)如果有人说万一出现有人为0或者负数怎么办,这好办,一开始先给每人分配0.01作为“底钱”就好了。
2. @马景铖的猜想是基于调查数据的,这点我非常赞赏。不过想提出一点意见(不好意思大过年的较真了哈哈):图2用线性回归做趋势分析是很好的,不过应该给出置信区间或p值等统计显著性指标。图3其实是有些误导的,因为你做的是一个累计平均,误差近似于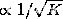 ,所以如果你把Confidence Band画出来也许会发现并没有显著偏离平均值。
,所以如果你把Confidence Band画出来也许会发现并没有显著偏离平均值。
3. 对于这个问题,大家可能关心两个问题:a)算法怎么实现的?b)先拿好还是后拿好?我认为后一个问题比较好回答,而且顺便想指出的是,即使存在和次序相关的“bug”,也非常容易“修正”:每次生成完分配方案以后把顺序打乱即可。
现在说说我是怎么分析这个问题的:
1. 首先同样是采样。我从微信群里抓取了37次分红的结果,为了使样本具有可比性,我只筛选了分红人数为5的样本,数据(一共37行)大概长这样:
[,1] [,2] [,3] [,4] [,5]
[1,] 0.26 1.64 1.50 0.51 1.09
[2,] 0.16 1.20 1.28 2.03 1.21
[3,] 0.03 0.43 0.01 0.51 0.02
[4,] 5.39 2.67 1.74 3.27 1.93
[5,] 0.31 0.07 0.07 0.33 0.22
[6,] 0.44 1.93 1.40 1.72 3.39
其中每一行是一次分红。例如:抽样的第三个红包总金额为1元,其中第2个人抽到了0.43元。
2. 然后一个我认为合理的假设(其实可能大家都已经默认了)是:我们的分布是齐次的。
记每个人分红的联合分布密度函数(joint pdf)为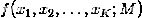 ,其中
,其中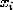 是第
是第 个人分到的金额(在我们的数据中
个人分到的金额(在我们的数据中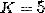 ),而
),而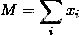 为总金额。那么齐次指的是:
为总金额。那么齐次指的是: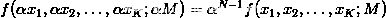 。用通俗的语言说一遍就是:如果你把总金额乘上一个倍数,新的分布和原来的分布是“相似”的。
。用通俗的语言说一遍就是:如果你把总金额乘上一个倍数,新的分布和原来的分布是“相似”的。
3. 有了齐次的假设,我们就可以把采集到的数据归一化(每一行除以它们的和),得到的每一个结果的意义是:每个人分到的钱占总金额的比例。
4. 箱形图
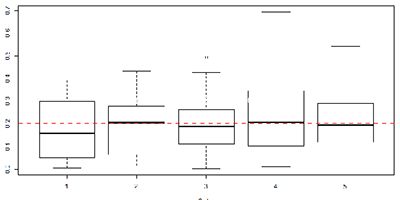
数据图
上图是37个样本的总结(横轴代表第几个人,纵轴是分到的比例)。从这幅图来看看不出啥,不过别急,这张图并不完全适合描述我们这个问题,因为每一个人的分红是相关的。
4. 直方图

数据图
没有评论。
5. 图上面我没看出啥明显的端倪,数字呢?
五组的均值:0.1704179 0.1915872 0.1899119 0.2418445 0.2062385
另外给出协方差矩阵:
V1 V2 V3 V4 V5
V1 0.0165548015 -0.005619991 0.0009090151 -0.009668083 -0.002175743
V2 -0.0056199905 0.015760475 -0.0017319045 -0.004626603 -0.003781977
V3 0.0009090151 -0.001731904 0.0149705394 -0.010626132 -0.003521518
V4 -0.0096680832 -0.004626603 -0.0106261322 0.031287609 -0.006366791
V5 -0.0021757429 -0.003781977 -0.0035215178 -0.006366791 0.015846028
协相关矩阵(以后会用到):
V1 V2 V3 V4 V5
V1 1.00000000 -0.3479277 0.05774181 -0.4248075 -0.1343338
V2 -0.34792765 1.0000000 -0.11275104 -0.2083490 -0.2393172
V3 0.05774181 -0.1127510 1.00000000 -0.4909873 -0.2286393
V4 -0.42480752 -0.2083490 -0.49098735 1.0000000 -0.2859395
V5 -0.13433382 -0.2393172 -0.22863934 -0.2859395 1.0000000
我们做一个Wald test,看看我们的数据是不是满足零假设(五组的期望均为0.2),略去计算过程,Wald test statistic = 0.0878, p值约为1,说明没有显著证据拒绝零假设。因此回答了问题b)先拿好还是后拿好?——都一样(从目前数据看来)。
6. 从经验分布反推模型是一个比较玄的事情,我们可以通过一些检验(正态检验、卡方检验)来从统计学上排除某个分布,但没有人能告诉你哪个分布是“对”的(All models are wrong, but some are useful. -- George E. P. Box)。可能和强迫症有关系,这个截断正态分布在我看来并不是一个漂亮的模型。狄利克雷分布(参见Dirichlet distribution)可能是个更好的选择:它要求这K个随机变量分布在0~1之间,且它们的和为1,这正是我们想要的!进一步想,既然目前没有明显证据支持每个人分到的比例不相同,那就从零假设(相同)出发。对于狄利克雷分布而言,就是所有的a(公式编辑器突然坏了,所以不写tex了,想看的去Wiki上找)都相同,代入到Dirichlet distribution页面中关于期望和方差的公式(K=5)得到E[Xi]=0.2,Var[Xi]=4/[25(5a+1)],Cor[Xi,Xj]=-0.25。和之前我们看到的数字(均值、方差、协相关)比是不是有一点点像?
7. 这是拟合的结果,拟合出的系数a(分别)为1.050646 1.237996 1.161214 1.443003 1.352875。
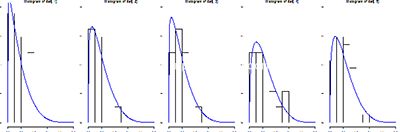
数据图
我相信,如果有更多的数据,我们可以更有把握(power)地判断a是否有显著区别,或者说,第几个拿最好?